
The desire for new solutions has never been greater in an era marked by fast digital transformation, where our everyday lives are seamlessly entwined with technology. As developers and consumers, we are at the crossroads of ease and complexity, looking for tools to comprehend and make sense of the huge digital expanse. This is where OCR APIs come into play. OCR, or optical character recognition, has become the crux of effective data extraction, and OCR APIs play an important part in this context.

Decoding The Pixel Puzzle: Solving The Puzzle
Consider the following scenario: You are handed a stack of identity documents, each containing a wealth of critical information. However, manually retrieving such information would be a time-consuming and error-prone task. This is the obstacle that OCR APIs overcome. They enable us to unleash the potential hidden inside pixels, converting word pictures into actionable data. The intricacies of multilingual material, various formats, and varying quality levels exacerbate the problem. But don’t worry, there is a solution that goes beyond simple recognition.
The Solution Is Here: Introducing The ID Document OCR API
Enter the ID Document OCR API, a ray of hope available at Zyla API Hub. This game-changing solution reduces the inherent difficulty of identification document extraction to a smooth digital experience. The delicate dance of obtaining data from passports, driver’s licenses, and IDs becomes a snap with this API, removing the constraints of human data entry.
A Neutral Evaluation Of The Features And Benefits
Let’s have a look at the incredible capabilities and benefits that the ID Document OCR API brings to the table without becoming too promotional:
- Precise Data Extraction: The API uses cutting-edge algorithms to extract data from texts with precision that rivals human input.
- Multilingual Support: In a world where people interact in a variety of languages, the API’s ability to decode and extract text from a wide range of linguistic backgrounds is very impressive.
- Beyond mechanical recognition, the API understands the context of the data, making sense of the links between phrases and fields.
- Increased Efficiency: Manual data input is a time-consuming chore. The API speeds up operations by shifting human efforts to higher-value jobs.
- Human mistakes are unavoidable, but the API reduces them by delivering consistent, error-free data extraction.
- Fortified Security: Dealing with sensitive information needs top-tier security. The API protects data privacy and adheres to high-security requirements.
However, we’d want to provide an example, which is why we provided the API with the URL of a Fake ID picture and were able to observe how it behaved.
As an example, “https://static01.nyt.com/images/2008/09/16/nyregion/license533.jpg” is provided:
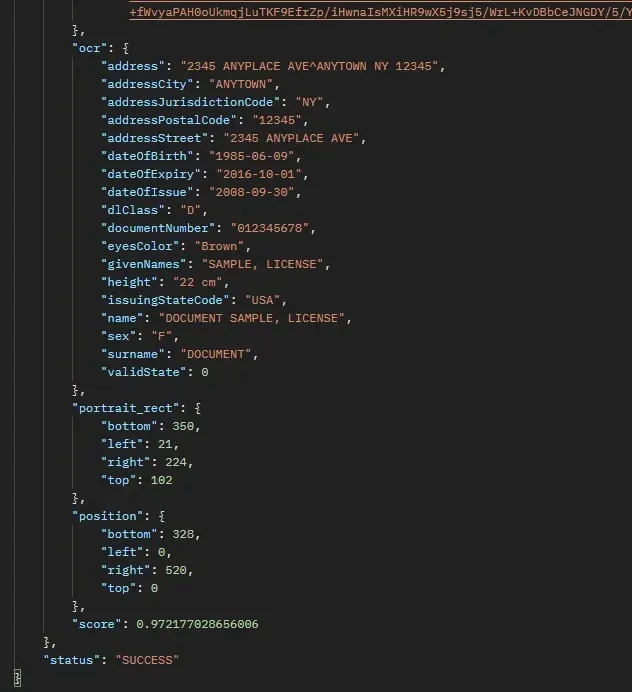
Starting Your Journey With The ID Document OCR API
Now that you’re familiar with the ID Document OCR API’s transformational potential, here’s a road map to get you started:
- Create a ZylaLabs API Hub ID Document OCR API developer account.
- To understand more about the ID Document OCR API endpoints and features, consult the API description.
- Create an API key to authenticate your queries.
- Use the offered code snippets and recommendations to integrate the API into your application.
- Deploy a comprehensive solution to empower your future content ID document analysis and security initiatives!
Related Post: ID Insights: Unraveling Data Through Document OCR APIs