
Use This Web Scraping News API To Get Articles From Yomiuri Shimbun
How do I obtain articles from the Yomiuri Shimbun that I need without having to pay for them? In this post, you will learn how to use a great API to extract significant data from routine or research studies.
If we wanted to obtain information from Yomiuri Shimbun (Shinjitai: Kyjitai:?) We must be aware that this is a Japanese newspaper composed of three anonymous societies: the Sociedad Anónima Yomiuri Shimbun of Tokyo, the Sociedad Anónima Yomiuri Shimbun of Osaka, and the Sociedad Anónima Yomiuri Shimbun of the East with offices in Fukuoka.
It was established on November 2nd, 1874, and currently has six main offices spread around Japan as well as a network of information with 352 informative locations in Japan and 34 worldwide. The company publishes 29 titles and is regarded as Japan’s largest periodical publishing company. It is regarded as a well-liked tabloid. We’re talking about a publication with a circulation that exceeds one million copies, making it the most widely distributed journal in the world up until 2007. Including is listed as the largest circulation daily in the Guinness Book of Records, with a total of 14 323 781 copies counted throughout morning and evening editions in 2002. Around 8 million subscriptions are estimated. collaborates with other significant newspapers including The Times of the United Kingdom and other American and Japanese newspapers.

Because artificial intelligence has so many benefits, more businesses are starting to use it. The use of an API, such as the Extractor of Data from Articles, can be one way to reduce the workload by utilizing the IA. Keep reading if you want to drastically reduce the amount of time you spend trying to extract information or data from news articles.
How does a data extractor API function?
Programs create an organized digital representation of information that originates from a different source through the process of data extraction. Automated data extraction processes are capable of performing a wide range of tasks, including data searching, website data collection, trend identification, information evaluation in databases, and so forth. To automatically gather data from the entire Internet, web scraping uses programming languages and algorithms.
It is necessary to use APIs like Article Data Extractor to obtain these outstanding results with less effort and time. Simply said, these APIs accelerate the entire process of obtaining the data you require and returning it to you in a matter of minutes. The only thing that needs to be done is to choose the publication’s parameters, such as the editor’s ID and access number, or the URL of any article from any publication. Obtaining all relevant information, including the article’s metadata, will take only a few minutes.
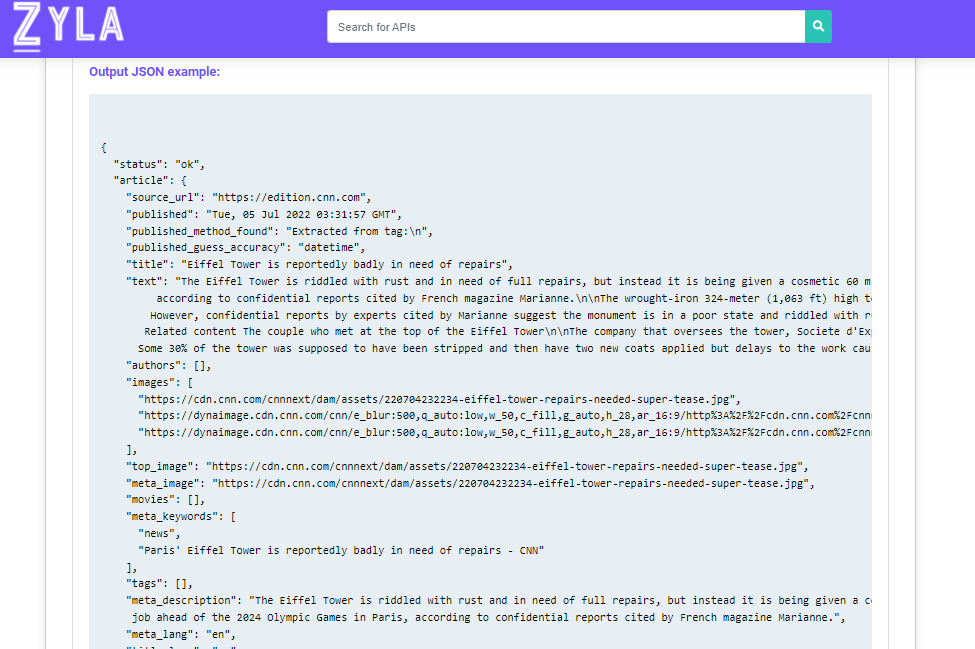
Article Data Extractor
Maybe you used someone else and got more information than you needed. However, if you need to get your news or information, this article extractor should have everything you need for you to concentrate on producing the most useful extracts from the articles. The advanced artificial intelligence that this extractor is using is quite effective at processing all of the data without any difficulty and obtaining it in useful formats in a matter of seconds.
Finding the appropriate resources may be challenging, but don’t worry; we’re here to help. This API will greatly speed up and aid in the development process for you. The extracted data is extremely valuable and provides the exact information needed to launch your project, expand your business, or meet any other need you may have. All the information and content you require can be efficiently recovered using this data extraction API. You can quickly obtain a significant amount of data that is useful for your business by simply entering the URL. Now is the time to stop wasting time and try out this API.