
News Scraper Scrape API: Extract Article Data From Daily Telegraph
You are aware that there is a proficient, quick, and efficient way to extract information from articles? The Article Data Extractor API is revolutionizing how information is extracted from any medium, and I’ll tell you all about it in this article.
The Daily Telegraph is a large-format British English newspaper published in London by the Telegraph Media Group and available throughout the United Kingdom and beyond. The newspaper was established by Arthur B. Sleigh in June of 1855 as The Daily Telegraph and Courier, and David and Frederick Barclay have owned it since 2004. In March 2014, it had a daily circulation of 523 048. The Daily Telegraph announced on October 10th, 2005, the addition of a sports section and a new independent business section.
A technique for extracting data from websites is called “web scraping.” It is a type of bot that visits many different websites and uses programming to gather, organize, and store information. Web scraping is used by the communication sector to understand their customers and what they want from their products. Online scraping can also assist organizations in automating processes (like data introduction) that would otherwise require human labor.
Do you want to scrape articles? In order to make the process of scraping articles as simple as possible for you, we’ve been working hard to determine the best method. So if you’re looking for a quick and simple method to scrape content, this article is for you. What if articles could be revoked in a matter of seconds? Imagine not having to remember to manually enter each article’s title, author, and URL. What would happen if you handled everything automatically? What scraping techniques for articles work the best? You’re in luck! In order to make the process of scraping articles as simple as possible for you, we’ve been working hard to determine the best method. Therefore, if you’re looking for a quick and simple technique for content rewriting, this article is for you.
What kind of operation does the Scrape Articles API perform?
How do APIs work? An API, or application programming interface, offers a way for programmers to connect their work with other systems or services. The use of APIs is possible in many different contexts, such as when other developers want to integrate their applications into larger systems, when businesses want to connect their systems with third-party applications, or when users want to access many services through a single interface.
The right place to go if you’re looking for a quick and simple way to extract data from articles is Article Data Extractor. The title, the author, the labels, and the article’s text are all automatically extracted by this API. There will be less work for you as you won’t need to manually fill out all of this information for each article. Just enter the URL, and Article Data Extractor will take care of the rest.
Article Data Extractor API.
You’re ready to use the best real-time news API currently available, right? If that is the case, we have big news for you. We take great pride in announcing that this new API is now accessible to all users. We are incredibly happy to provide the best real-time news API available. Interested in trying it out? You only need your unique access token to gain access to the API. Copy the article’s URL to obtain the relevant information, and the API will respond with information like this:
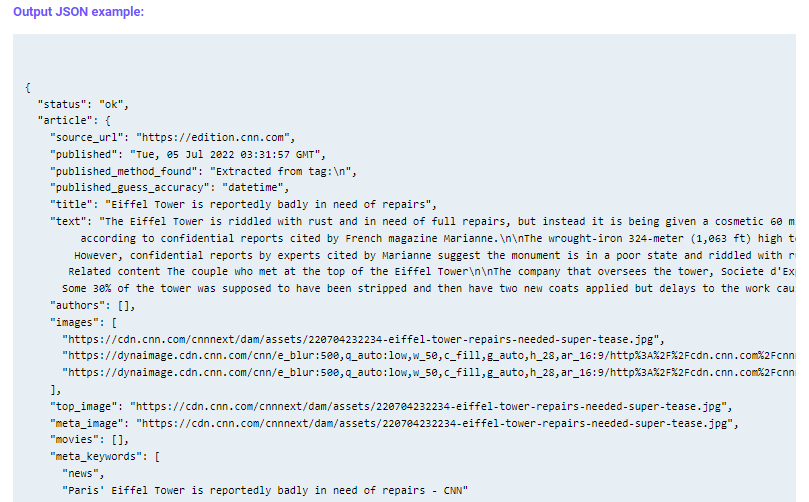
The solution is Article Data Extractor API if you want to quickly and easily find the right information. The web-based API known as Article Data Extractor API pulls data from text automatically and presents it in an easy-to-use style. You may find specific information, such as metadata, keywords, images, etc., by using the integrated AI engine. The data is also grouped by relevance to aid you in quickly finding what you need. You can still be connected by requesting a unique token after the API has finished. The integration process is also rather simple because a wide variety of programming languages are supported.