
We are excited to present cutting-edge Data Extraction APIs, which are driven by the most advanced Optical Character Recognition (OCR) technology. These APIs are design to improve how organizations manage ID papers and extract critical information, allowing you to process scanned or image-based IDs with exceptional precision. These APIs will quickly provide a structured JSON response including a plethora of vital data by just supplying the URL of the document you need to study.

An OCR API’s Role In Data Extraction
By turning scanned or image-based documents into machine-readable and structured data, an OCR (Optical Character Recognition) API plays a critical role in data extraction. The specified API takes an image of an ID as input and produces a structured JSON response including various bits of information derived from the ID.
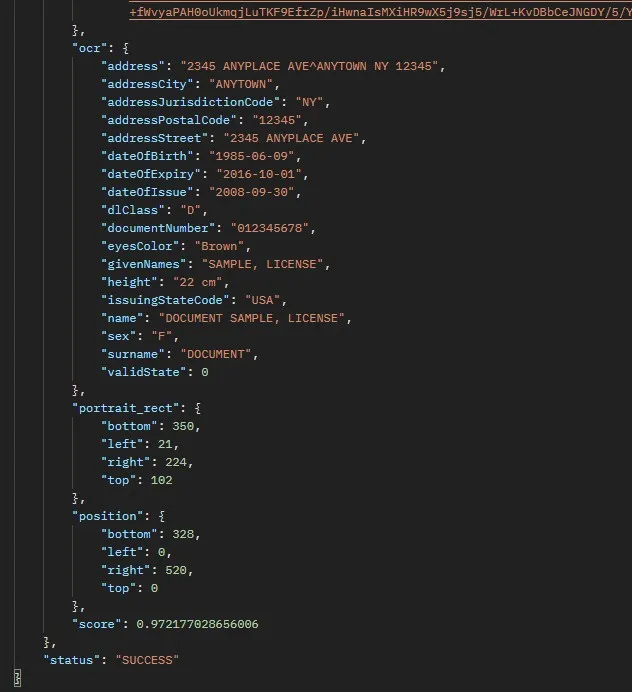
The URL of the document (ID) to study is the primary input for this API. The API then uses OCR technology to retrieve pertinent data from the image. The result is a JSON answer including fields such as name, surname, address, date of birth, expiration date, issuance date, document number, sex, and perhaps other data discovered in the ID.
This API is commonly use for the following purposes:
- Data Standardization: The API may help standardize information by delivering organized and consistent data in a database-friendly way. This guarantees that data from various ID papers is arrange consistently.
- Data Validation: By extracting essential information from the ID, the API enables for data validation. For example, it may check if the name matches the recorded information, determine if the ID is still valid by studying the expiration date, and more.
- Security Validations: Because the API can extract crucial information from IDs, it may use to perform security checks. By cross-referencing the retrieved data with their records, businesses, and organizations may use it to identify persons, verify identities, and prevent fraud.
- Automation and Efficiency: The API allows for the automation of data input operations, decreasing human labor and increasing efficiency in jobs involving the handling of huge amounts of ID papers.
Overall, an OCR API like the one presented here is critical for speeding up data extraction operations, improving accuracy, and allowing a variety of applications that require structured information from scanned or image-based documents.
Which OCR API Provides The Most Detailed Answers?
After examining numerous request options, we can conclude that the Zylalabs ID Document OCR API is one of the best since it is simple to use and produces excellent results.
“ID OCR” is the intended outcome. Driver’s licenses, passports, ID cards, and permanent residency cards are scan for structure text, pictures, and signatures. This API supports a diverse set of recognized national identities.
We gave the photo URL in this situation and can see how the API responded. We give the URL https://static01.nyt.com/images/2008/09/16/nyregion/license533.jpg in this instance.
Where Can I Read Everything About The ID Document OCR API?
- To begin, go to the ID Document OCR API and press the “START FREE TRIAL” button.
- After joining Zyla API Hub, you will be able to utilize the API!
- Make use of the API endpoint.
- After that, by hitting the “test endpoint” button, you may perform an API call and see the results shown on the screen.
Related Post: The Role Of An ID Card Text Extraction API In Modern Workflows: From Paper To Digital